deepseek的本地部署、使用教程、基本玩法
前言
就在上个月,deepseek突然爆火,凭借着超高的理解能力和推理能力各方面都已经和Chat gpt不相上下

而且还是开源的至二月十日,已经有四十四家国产平台接入deep seat。那么现在对于deep seat最大的问题就是不断的服务器繁忙
请稍后再试。那么这章就是、本地部署、使用教程、玩法。那么,开造!
本地部署
下载ollama
首先打开ollama【点击打开】的官网
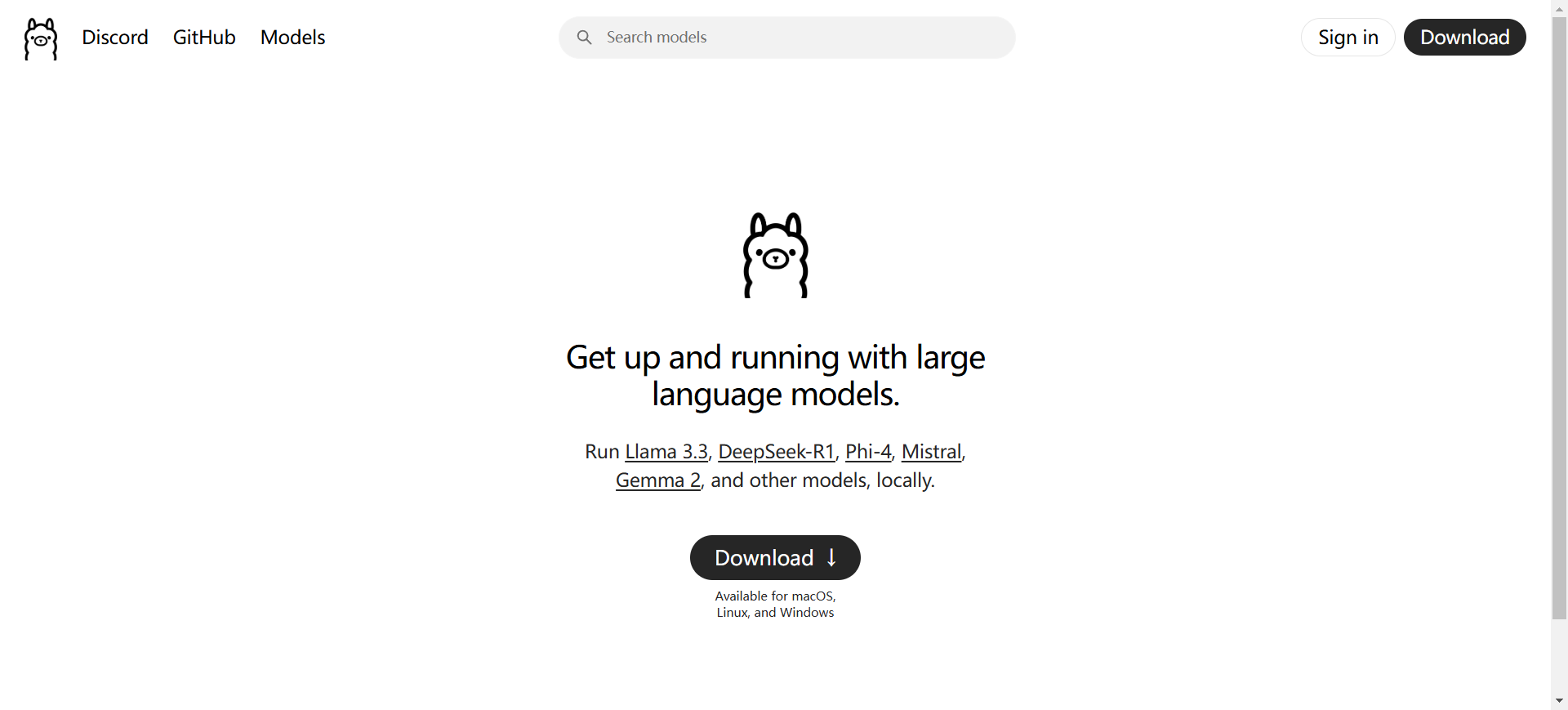
点击download,点击download for window,下载过程会有点慢。

下载后打开ollama,点击install就会安装。
部署deepseek
安装完后会有一个通知,点击就会来到命令行,输入ollama回车,出现一堆字符就是安装成功。然后回到ollama官网,返回到主页,点击deep seekR1,4G显存以下选择一点五b,8G选择7b或8b,12G到16G选择14b,24G选择32b

不知道显存是多少,可以按Esc加shift加ctrl打开任务管理器,选择第二个下滑,找到GPU,专用GPU内存就是显存,然后根据自己的显存选择,点击复制,粘贴进命令行即可。
如果速度在后期变得很慢,可以按ctrl加c停止下载,再粘贴下载命令,回车即可,如果还是这样,可以多试几次就行了。
看到“Send a message (/? for help)”就证明安装好了,然后用小学生方法打开cmd(这个我不用讲了吧),输入拉ollama list即可查看已安装的模型name就是模型名称,其他不用管,再次输入安装命令即可启动模型。看到这些就是启动成功。
使用教程
在谷歌(edge也一样)扩展搜索Page Assist添加扩展天下,然后点击扩展,点击Page Assist,把模型改成已部署的模型,再去设置,把语言改成简体中文,edge同理。
玩法
玩法一:
对于deepseek非常强的理解能力,不需要用花言巧语来装扮问题,直接用跟熟人说话的语气即可。我就随便问一句
(我不想放图了,看到这里不去试试吗?)
当然可以打开联网搜索来弥补底显存模型的智商空缺过程会有点慢,需要耐心等待。ok写完了,这个内容还算满意,毕竟出来的内容和速度是与显存有关,8G显存能这样已经不错了。
玩法二:
如果deepseek写出来的东西听不懂,可以告诉deepseek说人话。比如问dlss是什么?告诉deepseek说人话
(我又不想放图了…)
这样就可以让deepseek写出来的更通俗易懂。
写在最后
但其实对于配置不好的哥们生成出来的跟智障一样。所以我个人推荐显存,没有八g的最好直接用官方网站服务器繁忙等攻击结束就行了。